Зачем бороться за Unicode
и кому все это нужно
Итак, тема такова. За Юникод бороться жизненно необходимо по ряду причин.
Все традиционные кодировки (которые надстроены над таблицей ASCII) способны к сожалению только на то, чтобы показывать латиницу (минимальную, ту самую, которая ASCII) + некий набр символов, который надстроен над этим самым ASCII. Поэтому при сохранении файла в традиционной 8-битовой кодировке (текстового, не HTML - поскольку в HTML есть entities) в нем принципиально невозможно набрать следущий простейший текст:
Вчера я гостил на Mühlheimer ßtraseДа, есть вариант с HTML-entities (например ß), но что если надо на одной странице набрать иврит и русский? русский и деванагари? китайский и венгерский? В двух разных кодовых таблицах на одном и том же знакоместе могут оказаться иероглиф и арабская буква, например.
В кодировке Windows-1251 просто нету немецких глифов, которые не входят в ASCII - потому что все что вошло в таблицу помимо базового ASCII - русские буквы. Unicode изначально ставил задачей выдать каждому знаку любого мирового алфавита свой уникальный номер, чтобы кодовые таблицы разных языков не пересекались. Это проблема номер один - устранить пересечения кодовых таблиц. Проблема номер два - все программы, обрабатывающие текст хоть в каком-нибудь виде (от банального XML-парсера до InDesign), обязаны быть “осведомлены” о супе из разных кодировок, то есть:
- всегда помнить, в каком же идиотском чарсете набран каждый цельный кусок текста
- при перемещении текста из одной кодовой таблицы в другую перекодировать текст на лету (с возможной потерей символов)
- поддерживать трансляцию основных символов (пробел, конец строки и пр.) как в XML-парсерах, при этом корректно обрабатывать, например, entities
- Microsoft Word
- InDesign, Photoshop, Illustrator
- Все Cocoa-программы в MacOS X
- Большая часть Windows
Именно потому, что есть Юникод, можно совершенно спокойно набирать одним шрифтом документ на немецком и руском в InDesign - потому что по количеству знаков Юникода и количество доступных глифов в шрифте (посмотрите например на таблицу символов шрифта Minion Pro). До Unicode-aware приложений, например, верстку в QuarkXPress приходилось набирать двумя шрифтами - у одного на определенных местах была диакритика, у другого - русские буквы. И переключаться между этими шрифтами.
Unicode представляет собой как-бы “универсально предсказуемый” формат для всего софта, который производится в настоящее время. То есть, например, пользоваться кодировкой Win-1251, и надеяятся что при этом корректно заработает, например, SOAP - нереально, поскольку большинство реализаций веб-сервисов рассчитывают поулчать на входе и выходе Unicode. Если я экспортирую XML из InDesign и хочу потом на его основе генерировать веб-страницу - я ожидаю Unicode. Если я хочу опубликовать информацию кому угодно (essentially), я опубликую ее в Unicode поскольку знаю что там уж точно ничего не потеряется. Помимо прочего, любая программа, которая не работает в Unicode, но при этом хочет открывать все возможные виды кодировок, неизбежно обратастает интерфейсами конверсии этих самых кодировок, которые когда работают, когда нет (в американской версии InDesign 2 так и не работает выбор кодировки при помещении текста на полосу, хотя меню такое там есть), и более того - становится слишком сложно предсказать все то, что предсказать невозможно (каждый компонент, который обрабатывает текст, нужно дополнительно “затачивать” под то, чтобы оно “кушало” хотя бы некий набор кодировок (а для хорошего overzicht'а их количества можно даже в меню браузера заглянуть разок). В случае же с Unicode - все более-менее понятно. Не говоря уж о том, что Unicode - единственный путь к ПО моей мечты - которое пишется одновременно для всех языков, выпускается в одной интернациональзной версии, поддерживает лингвистические модули и имеет англоязычный интерфейс. Adobe уже близки, Microsoft (в своих макинтошных продуктах) сильно отстает из-за ублюдочного пользования системой шрифтов и методов ввода
Замечательная статья в Joel on Software на тему всех этих проблем недавно произвела феноменальный шум в Сети - и не зря, в ней он наконец-то больно прошелся по товарищам, из-за которых “программа Х не печатает по-русски”. Замечательное англоязычное чтение.
Вот кстати пример: все парсеры XML по умлочанию заточены под Unicode.Заканчивается это тем, что я ставлю себе браузер (которым, надо признать, русских людей пользуется немного) и вижу, что дескать...
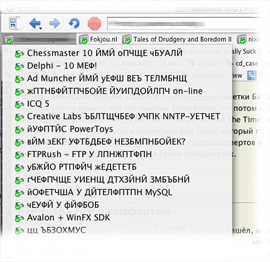
Фиды в юинкоде оный браузер показывает совершенно нормально.
Дабы подытожить: зачем нужен Unicode? Чтобы кодировка была одна.